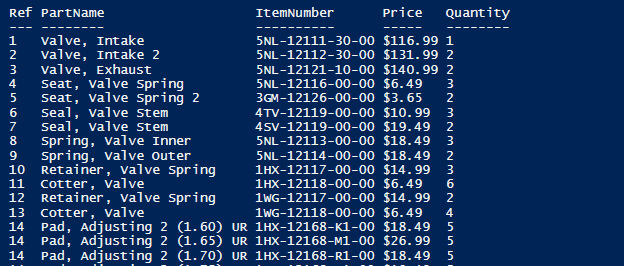
I need to scrape a bunch of webpages to obtain part numbers and other information. I have been unsuccessfully trying for two days and figured it was time to ask the experts. The data I’m looking to capture is: Ref#, PartName,Price,Qty
$URL = https://www.yamahapartshouse.com/oemparts/a/yam/500449cff8700209bc790600/valve
$Request = Invoke-WebRequest -Uri $URL -UseBasicParsing
An example of the HTML for a single part looks like the following:
<div class="partlistrow">
<form action="/cart/addoempart" data-name="Valve, Intake" data-qoh="0" data-sku="5NL-12111-00-00" id="add_1_5NL-12111-00-00" method="post">
<input type="hidden" id="manf_1" name="manf" value="YAM" />
<input type="hidden" id="assembly_1" name="assembly" value="500449cff8700209bc790600" />
<input type="hidden" id="sku_1" name="sku" value="5NL-12111-00-00" />
<div class="c0"><span>1</span></div>
<div class="c1">
<div class="c1a" style="width:100%;display:table;table-layout:fixed;">
<span style="white-space: nowrap;">Valve, Intake</span>
</div>
<div class="clear"></div>
<div class="c1b">
<a href="/oemparts/p/yamaha/5nl-12111-00-00/valve-intake"><span class="itemnumstrike">5NL-12111-00-00</span></a> <a href="/oemparts/p/yamaha/5nl-12111-30-00/valve-intake"><span class="itemnumnew">5NL-12111-30-00</span></a>
</div>
<div class="clear"></div>
</div>
<div class="c2"><span class="dbl">$116.99</span></div>
<div class="c3"><input type="text" id="qty_1" name="qty" class="input_1 center required qtyinput" value="1" /></div>
<div class="c4"><input type="submit" id="addtocart_1_5NL-12111-00-00" class="ui ui-icon-smadd btnpartadd" value="Add" /></div>
<div class="clear"></div>
</form>
</div>
When I search around on how to best do this, there doesn’t seem to be as much info as I would expect. There is some talk about using “parsedhtml”, however, it is blank in my case. There are other references to use regex, but I haven’t had much success with that either. Can someone please point me in the best direction on how to go about this. I have (42) pages that I need to pull info for. Any help is greatly appreciated.
Key HTML TAGS:
<div class="c0"><span>1</span></div>
<div class="c1a" style="width:100%;display:table;table-layout:fixed;">
<span style="white-space: nowrap;">Valve, Intake</span>
</div>
<div class="c2"><span class="dbl">$116.99</span></div>
<div class="c3"><input type="text" id="qty_1" name="qty" class="input_1 center required qtyinput" value="1" /></div>